CbxConverter: PDF import
There seem to be two variants of pdf comic books.
First variant contains just images (i.e. text is part of the images) and my recommended tool for converting it to cbz format would be CbrPdfConverter. It is very fast and it looks like it's extracting images without any manipulation so it's keeping best possible quality. As it generates cbz files it can be easily compressed further with CbxConverter. My only problem with CbrPdfConverter is not too efficient interface, i.e. no drag-and-drop and file selection dialog resetting each time to default location.
Second pdf variant has text separated from images. Using CbrPdfConverter with it produces images without text - text has to be rendered first. PDF to image application works with it but - at least on my PC with 32-bit OS - often fails after converting half of the document. It seems to have serious memory leak and with each produced page image it moves toward memory limit.
As Ghostscript is also capable of converting pdf to images I've used
it as external tool for importing PDF files into CbxConverter. Ghostscript has to be downloaded separately and path to gswin32c.exe has
to be set in CbxConverter settings:
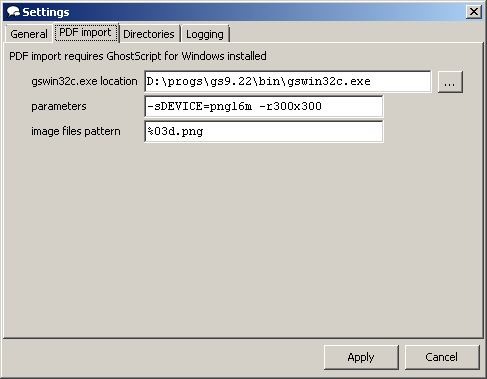
In default configuration pdf is converted with 300 dpi density to png images. I havent found settings that would generate text with antialiasing yet (apparently alphabits don't work with files I've tested and Ghostscript 9.22), but after resizing images later to 50% using CbxConverter output cbz files seem acceptable.
Once again, resizing down output to 50% (or even more, depending on source - some pdf files may render with width like 4000 px despite poor image quality and low information density) is important, otherwise you would get absurdly large output file. 1000 px width image after resizing might look as good as rendered 4000 px png.
Pdf rendering is rather slow (takes minutes per file) and takes place immediately after dropping files into CbxConverter - be patient.
After pdf is rendered - Ghostscript generated image files for each page - it is no different than using cbz/cbr as source file. Extracted images are stored in /tmp subdirectory or directory specified by user and can be manually deleted to get rid of unnecessary pages. As png format is selected by default for these images application in version 0.11 is not able to read image sizes so if your source pdf is unusual you may need to check image resolution manually before applying scaling.
Back to CbxConverter